One of the great additions buried in iOS 7 is the text to speech synthesizer API. This provides an offline speech synthesis capability with support for over 30 voices including country specific variations, controls to adjust speech rate, pitch, volume and a delegate protocol to allow interaction during speech.
Speech Synthesizer API
The AVSpeechSynthesizer class was introduced with iOS 7 and is the entry point for producing synthesized speech from text. The key properties and methods of AVSpeechSynthesizer, the delegate and related classes are shown below:
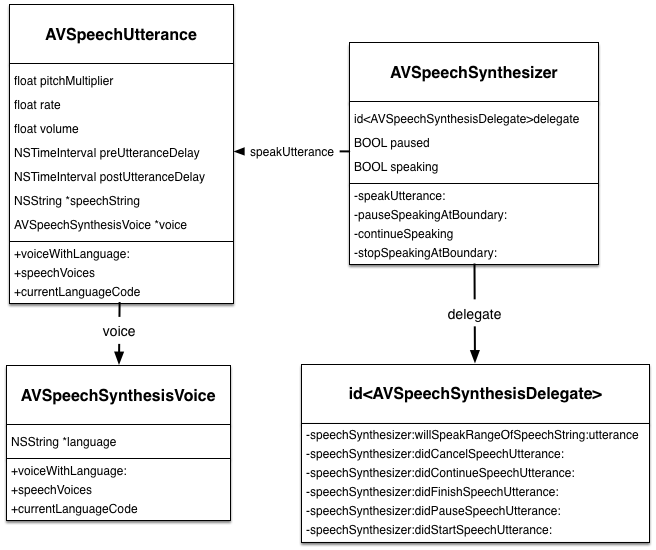
The basic steps to generate speech from text are as follows:
-
Create an instance of
AVSpeechSynthesizerand if required set it’s delegate (see later):AVSpeechSynthesizer *synthesizer = [[AVSpeechSynthesizer alloc] init]; synthesizer.delegate = self; -
For each section of text to be spoken create an
AVSpeechUtteranceand optionally set parameters for the pitch, rate, volume, pre or post delay and the voice.AVSpeechUtterance *utterance = [[AVSpeechUtterance alloc] initWithString:text]; utterance.pitchModifier = 1.25; // higher pitch -
Pass the utterance to the AVSpeechSynthesizer instance. Multiple utterances can be created and queued up to be spoken in turn. This is useful for longer texts where you want a delay between sections or where you want different sections to be emphasised by varying the speed or pitch.
[synthesizer speakUtterance:utterance];
Voices
By default an utterance will use a default voice for the current user locale. However what is interesting is that you can create voices appropriate for languages and locales different from the default. Creating a new voice is as simple as creating an instance of AVSpeechSynthesisVoice and setting the language property to the correct language code string for a supported language.
At the time of writing, iOS 7.0.4 supports 36 distinct voices. This includes local language variants such as UK and US versions of English. I will leave it to you to judge how accurate some of these voices are.
Unfortunately Apple does not list all of the supported language codes in the class documentation but mentions they need to be BCP-47 codes. Luckily you can retrieve the codes for the full list of supported languages with the AVSpeechSynthesisVoice class method +speechVoices. The list is shown below for reference with both the display name, for the English locale, and the BCP-47 language code you need when creating the voice. Note that the language codes use a hyphen not an underscore:
Arabic (Saudi Arabia) - ar-SA
Chinese (China) - zh-CN
Chinese (Hong Kong SAR China) - zh-HK
Chinese (Taiwan) - zh-TW
Czech (Czech Republic) - cs-CZ
Danish (Denmark) - da-DK
Dutch (Belgium) - nl-BE
Dutch (Netherlands) - nl-NL
English (Australia) - en-AU
English (Ireland) - en-IE
English (South Africa) - en-ZA
English (United Kingdom) - en-GB
English (United States) - en-US
Finnish (Finland) - fi-FI
French (Canada) - fr-CA
French (France) - fr-FR
German (Germany) - de-DE
Greek (Greece) - el-GR
Hindi (India) - hi-IN
Hungarian (Hungary) - hu-HU
Indonesian (Indonesia) - id-ID
Italian (Italy) - it-IT
Japanese (Japan) - ja-JP
Korean (South Korea) - ko-KR
Norwegian (Norway) - no-NO
Polish (Poland) - pl-PL
Portuguese (Brazil) - pt-BR
Portuguese (Portugal) - pt-PT
Romanian (Romania) - ro-RO
Russian (Russia) - ru-RU
Slovak (Slovakia) - sk-SK
Spanish (Mexico) - es-MX
Spanish (Spain) - es-ES
Swedish (Sweden) - sv-SE
Thai (Thailand) - th-TH
Turkish (Turkey) - tr-TR
The following code snippet would, for example, set the utterance to use an Australian voice:
utterance.voice = [AVSpeechSynthesisVoice voiceWithLanguage:@"en-AU"];
Update 13 July 2014, iOS 8 added support for the Hebrew language
AVSpeechSynthesisDelegate
If you need to interact with the speech synthesis you can set the delegate of the AVSpeechSynthesizer object and implement one or more of the optional AVSpeechSynthesisDelegate protocol methods.
Delegate methods allow you to respond when the synthesizer starts, pauses, resumes, finishes or cancels speaking an utterance. Refer back to the earlier class diagram for the names of each of the delegate methods. The most interesting method for me is the -speechSynthesizer:willSpeakRangeOfSpeechString:utterance: method which is called just before each unit of text (mostly a word) will be spoken by the synthesizer. The method call includes the character range in the string being spoken making it easy to highlight the text as it is being spoken.
SpeakEasy
To test out the speech API’s I have created a small Xcode project called SpeakEasy which you can find in my GitHub repository. It is a single view controller App with a simple user interface as shown in the screenshot below:
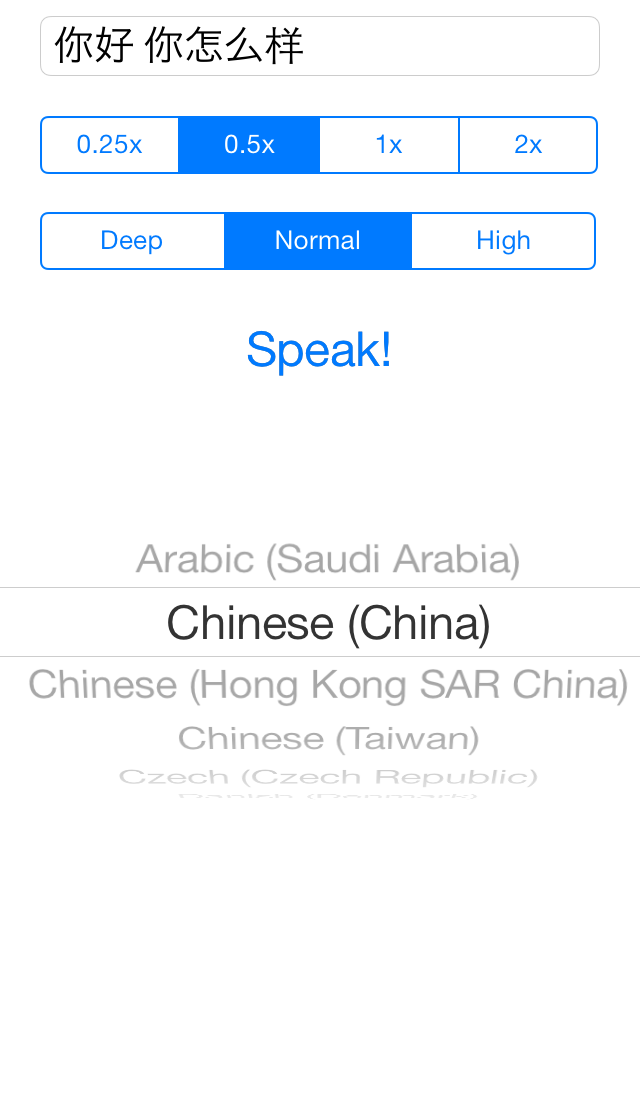
The user types some text in the text field at the top of the screen, selects a language from the picker and then taps “Speak!” to hear the text spoken in the chosen voice. The speed and pitch of the speech can be modified and as an extra bonus each word in the text is highlighted as it is spoken. It is up to the user to select a language appropriate to the text.
Using A Picker to Select The Language
There is a lot of setup code in the view controller that is not directly related to the speech synthesis API’s that I will mostly skip over. A UIPickerView is used to allow the user to select from the list of available speech synthesis voices. To populate the picker view I use two properties:
@property (strong, nonatomic) NSArray *languageCodes;
@property (strong, nonatomic) NSDictionary *languageDictionary;
The NSArray stores the BCP-47 style language codes (like “en-GB”) that are required to configure the voice. This array is ordered based on the sorted order of the corresponding display names for each language code. The dictionary provides a quick look up of the display name for each language code based on the users current locale.
As previously mentioned we can get an array of all available voices using the speechVoices class method of AVSpeechSynthesisVoice. The display name corresponding to the language code is obtained using the displayNameForKey:value: method of NSLocale. Note that this display name is itself locale specific so the sort order will vary with the user locale.
- (NSDictionary *)languageDictionary {
if (!_languageDictionary) {
NSArray *voices = [AVSpeechSynthesisVoice speechVoices];
NSArray *languages = [voices valueForKey:@"language"];
NSLocale *currentLocale = [NSLocale autoupdatingCurrentLocale];
NSMutableDictionary *dictionary = [NSMutableDictionary dictionary];
for (NSString *code in languages) {
dictionary[code] = [currentLocale displayNameForKey:NSLocaleIdentifier value:code];
}
_languageDictionary = dictionary;
}
return _languageDictionary;
}
The array of sorted language codes is easily generated using the keysSortedByValueUsingSelector: method on the dictionary as follows:
- (NSArray *)languageCodes {
if (!_languageCodes) {
_languageCodes = [self.languageDictionary keysSortedByValueUsingSelector:@selector(localizedCaseInsensitiveCompare:)];
}
return _languageCodes;
}
Once we have these two data structures implementing the UIPickerViewDelegate methods to configure the picker is simple:
- (NSInteger)numberOfComponentsInPickerView:(UIPickerView *)pickerView {
return 1;
}
- (NSInteger)pickerView:(UIPickerView *)pickerView numberOfRowsInComponent:(NSInteger)component {
return [self.languageCodes count];
}
The UIPickerViewDataSource method to configure the title of each row is shown below. Note that we first get the language code that corresponds to the picker row and then use it to lookup the actual display name in the dictionary.
- (NSString *)pickerView:(UIPickerView *)pickerView titleForRow:(NSInteger)row forComponent:(NSInteger)component {
NSString *languageCode = self.languageCodes[row];
NSString *languageName = self.languageDictionary[languageCode];
return languageName;
}
For completeness I will also show the delegate method that handles selection of a row in the picker:
- (void)pickerView:(UIPickerView *)pickerView didSelectRow:(NSInteger)row inComponent:(NSInteger)component {
self.selectedLanguage = [self.languageCodes objectAtIndex:row];
NSUserDefaults *preferences = [NSUserDefaults standardUserDefaults];
[preferences setObject:self.selectedLanguage forKey:UYLPrefKeySelectedLanguage];
[preferences synchronize];
}
This simply stores the selected language code in a property and then also stores it in a user preferences file so that it can be restored when the App restarts. I don’t show it here but I perform similar state preservation and restoration actions for the other elements of the user interface (see State Restoration for other posts on the topic).
Speaking the Text
The full method that is called when the user taps the speak button is shown below:
- (IBAction)speak:(UIButton *)sender {
if (self.textInput.text && !self.synthesizer.isSpeaking) {
AVSpeechSynthesisVoice *voice = [AVSpeechSynthesisVoice voiceWithLanguage:self.selectedLanguage];
AVSpeechUtterance *utterance = [[AVSpeechUtterance alloc] initWithString:self.textInput.text];
utterance.voice = voice;
float adjustedRate = AVSpeechUtteranceDefaultSpeechRate * [self rateModifier];
if (adjustedRate > AVSpeechUtteranceMaximumSpeechRate) {
adjustedRate = AVSpeechUtteranceMaximumSpeechRate;
}
if (adjustedRate < AVSpeechUtteranceMinimumSpeechRate) {
adjustedRate = AVSpeechUtteranceMinimumSpeechRate;
}
utterance.rate = adjustedRate;
float pitchMultiplier = [self pitchModifier];
if ((pitchMultiplier >= 0.5) && (pitchMultiplier <= 2.0)) {
utterance.pitchMultiplier = pitchMultiplier;
}
[self.synthesizer speakUtterance:utterance];
}
}
Some notes of explanation:
-
Updated 10-Jan-2014: As I mentioned previously it is possible to queue multiple utterances to the speech synthesizer. To avoid that “feature” when you repeatedly tap the Speak button I have added a test to see if the synthesizer is already speaking (
self.synthesizer.isSpeaking) before queuing a new utterance. -
Assuming we actually have some text to speak in the
UITextFieldand the synthesizer is not already speaking we first create the speech synthesis voice (AVSpeechSynthesisVoice) using the currently selected language code.AVSpeechSynthesisVoice *voice = [AVSpeechSynthesisVoice voiceWithLanguage:self.selectedLanguage]; -
A new utterance is created using the input text from the user and the voice is set.
AVSpeechUtterance *utterance = [[AVSpeechUtterance alloc] initWithString:self.textInput.text]; utterance.voice = voice; -
The
rateModifiermethod (not shown) returns a value 0.25, 0.5, 1.0 or 2.0 depending on the value selected by the user that is used to adjust the default value (AVSpeechUtteranceDefaultSpeechRate). The rate is checked to ensure it is betweenAVSpeechUtteranceMinimumSpeechRateandAVSpeechUtteranceMaximumSpeechRate- actual values are not documented but currently seem to be 0.0 and 1.0.float adjustedRate = AVSpeechUtteranceDefaultSpeechRate * [self rateModifier]; ... utterance.rate = adjustedRate; -
The
pitchModifiermethod (also not shown) returns a value of 0.75 (deep), 1.0 (normal) or 1.5 (high) depending on the value selected by the user that is used to set the pitch multiplier of the utterance. The permitted range is from 0.5 to 2.0 with the default being 1.0 but I find the extremes do not give great results.float pitchMultiplier = [self pitchModifier]; ... utterance.pitchMultiplier = pitchMultiplier; -
Finally with the utterance configured it is passed to the instance of
AVSpeechSynthesizerto be spoken.[self.synthesizer speakUtterance:utterance];
Implementing the AVSpeechSynthesisDelegate
To finish up I will implement the delegate methods to highlight the words as they are being spoken. First step is to add AVSpeechSynthesisDelegate to the list of protocols implemented by the view controller:
@interface UYLViewController () <UITextFieldDelegate,
UIPickerViewDelegate, UIPickerViewDataSource,
AVSpeechSynthesizerDelegate>
I have not shown it so far but the AVSpeechSynthesizer instance is setup with a lazy initialisation when first accessed as follows:
- (AVSpeechSynthesizer *)synthesizer {
if (!_synthesizer) {
_synthesizer = [[AVSpeechSynthesizer alloc] init];
_synthesizer.delegate = self;
}
return _synthesizer;
}
With the delegate set, we can implement the method to inform us when a word (strictly a unit of speech) is about to be spoken:
- (void)speechSynthesizer:(AVSpeechSynthesizer *)synthesizer
willSpeakRangeOfSpeechString:(NSRange)characterRange
utterance:(AVSpeechUtterance *)utterance {
NSMutableAttributedString *text = [[NSMutableAttributedString alloc] initWithString:self.textInput.text];
[text addAttribute:NSForegroundColorAttributeName
value:[UIColor redColor] range:characterRange];
self.textInput.attributedText = text;
}
This method creates a mutable attributed string from the plain non-attributed NSString object of the UITextField. Then using the range of the characters about to be spoken a red foreground color attribute is added to the string and then used to set the attributed string of the UITextField for display. This should have the effect of highlighting each word just as it is about to be spoken.
We also need to implement the delegate method to tell us when a speech utterance finishes. We can use this method to remove the foreground color text attribute from the final word of the text input string:
- (void)speechSynthesizer:(AVSpeechSynthesizer *)synthesizer
didFinishSpeechUtterance:(AVSpeechUtterance *)utterance {
NSMutableAttributedString *text = [[NSMutableAttributedString alloc]
initWithAttributedString:self.textInput.attributedText];
[text removeAttribute:NSForegroundColorAttributeName
range:NSMakeRange(0, [text length])];
self.textInput.attributedText = text;
}
Now when a string of text is spoken each word is, in turn, highlighted in red:

How Well Does It Work?
In playing with the example App I have been pretty impressed by the accuracy of the speech synthesis and in particular the language support. It is not perfect but on the whole it does a reasonable job. For example, compare the word “cerveza” when spoken with the Spanish (Spain) and Spanish (Mexico) voices.
Of course not all voices are capable of reading all text, especially those using a non latin based alphabet. Try it for yourself using some of the following google translations of the text “Hello how are you”:
- Chinese: 你好你怎么样
- Arabic: مرحبا كيف حالك (note text read from right-to-left)
- Greek: Γεια σας πώς είστε
- Hindi: हैलो आप कैसे हैं
- Japanese: こんにちは、どのようにしている
- Korean: 안녕하세요 어떻게 지내
- Russian: Привет, как
- Thai: สวัสดีเป็นอย่างไรบ้าง
One final note if you are running the example code in the simulator rather than on a device you will get a number of error messages on the debug console:
ERROR: AVAudioSessionUtilities.h:88: GetProperty_DefaultToZero:
AudioSessionGetProperty ('disa') failed with error: '?ytp'
ERROR: >aqsrv> 65: Exception caught in (null) - error -66634
As far as I can tell these are harmless and do not occur when running on a device but let me know if you find otherwise.
Wrapping Up
The need for text to speech synthesis is maybe not a requirement that will come up in many Apps but it is still a very nice addition to iOS 7. As always you can find the sample Xcode project in my GitHub CodeExamples repository.